Where do diffusion models generate the content of text?
Building on recent works that show how altering key and value matrices in cross-attention layers can control concept generation in diffusion models, we identify which attention layers generate textual content.
Injection modifies key and value matrices in cross-attention layers to influence concept generation in U-Net-based diffusion models like Stable Diffusion. It simply replaces the text embeddings that are the input to the cross-attention layer with the embeddings of the target prompt. However, it is ineffective for models with joint attention, such as SD3 and FLUX, where text embeddings evolve across layers.
Patching identifies attention layers by caching and injecting activations from a target prompt during another generation. By modifying only text-related activations, patching remains effective across different model architectures.

Overview of the localization approaches.
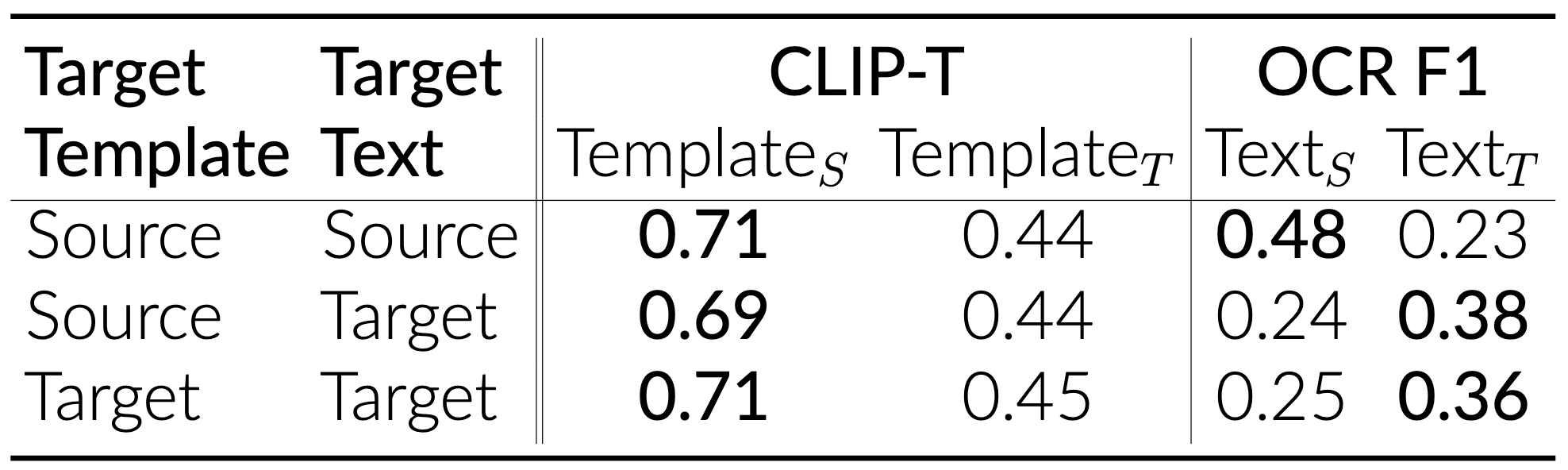
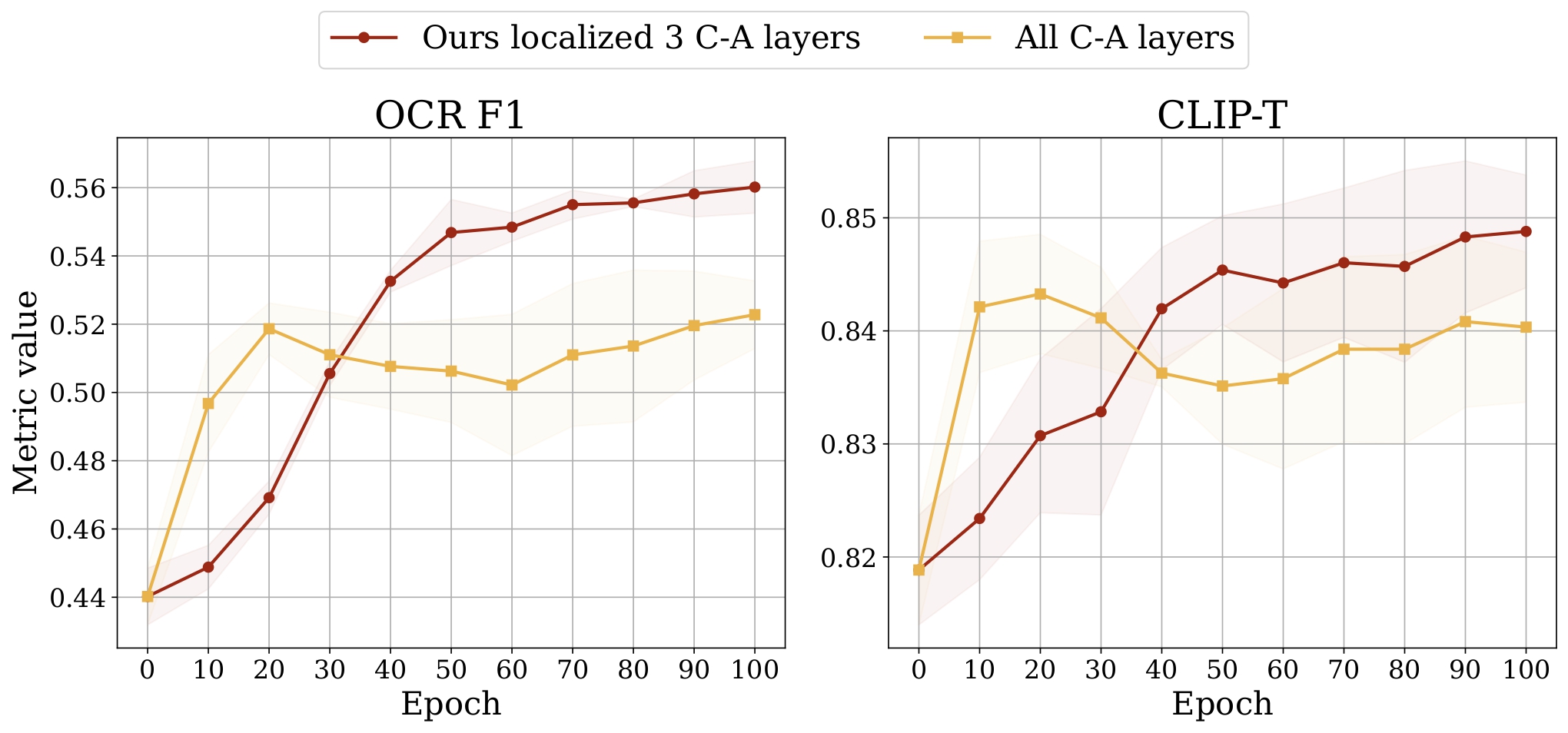
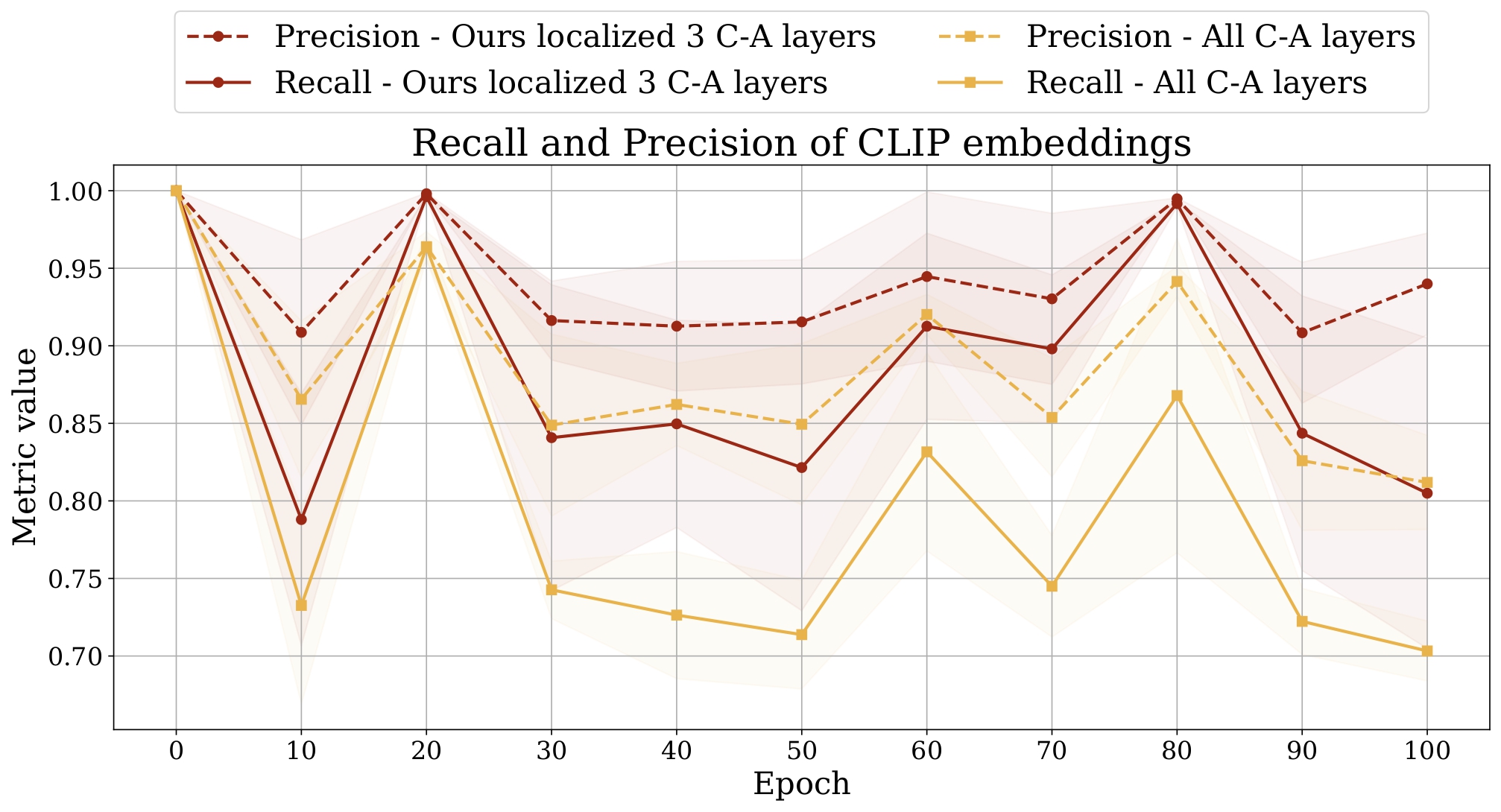
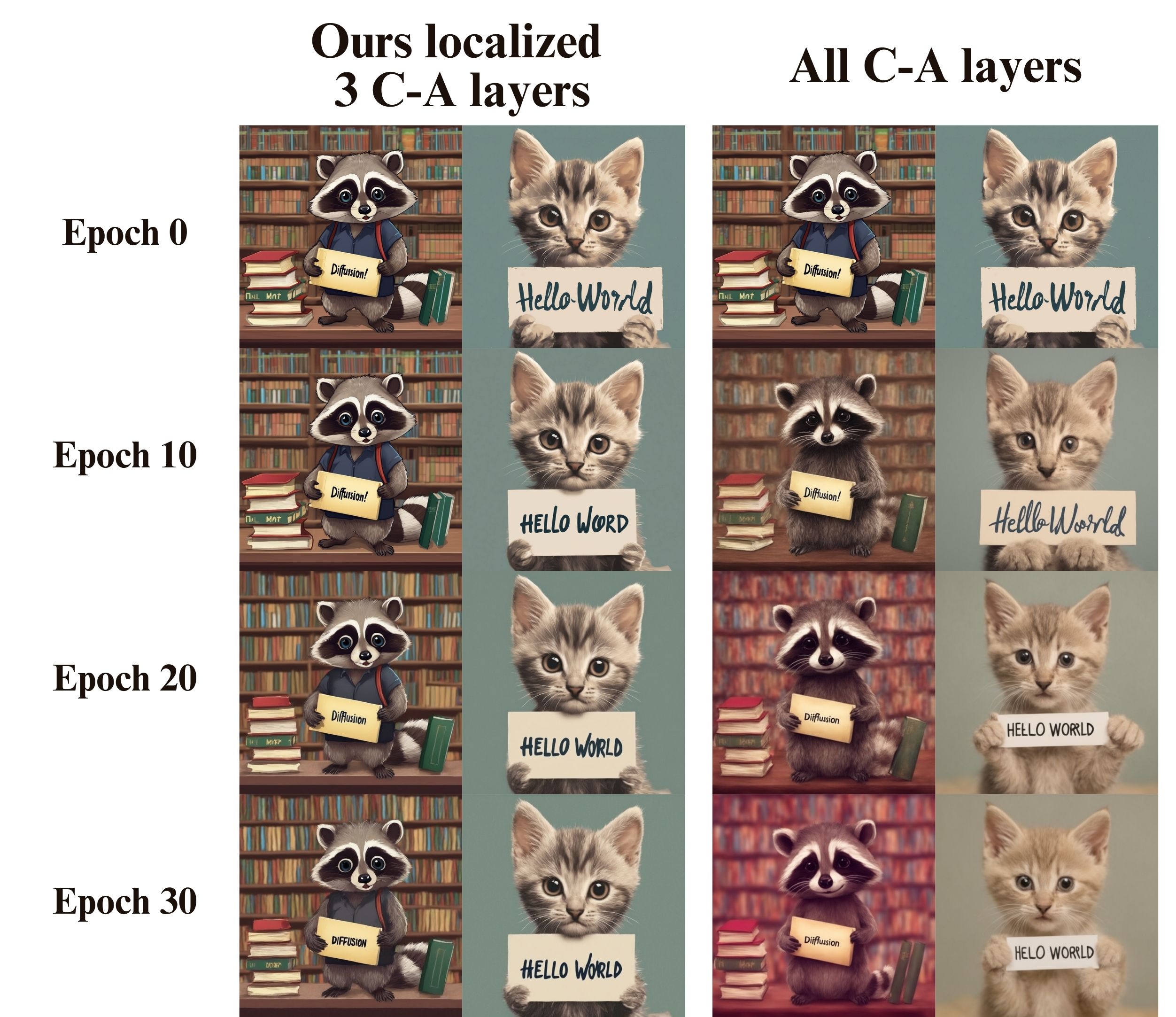
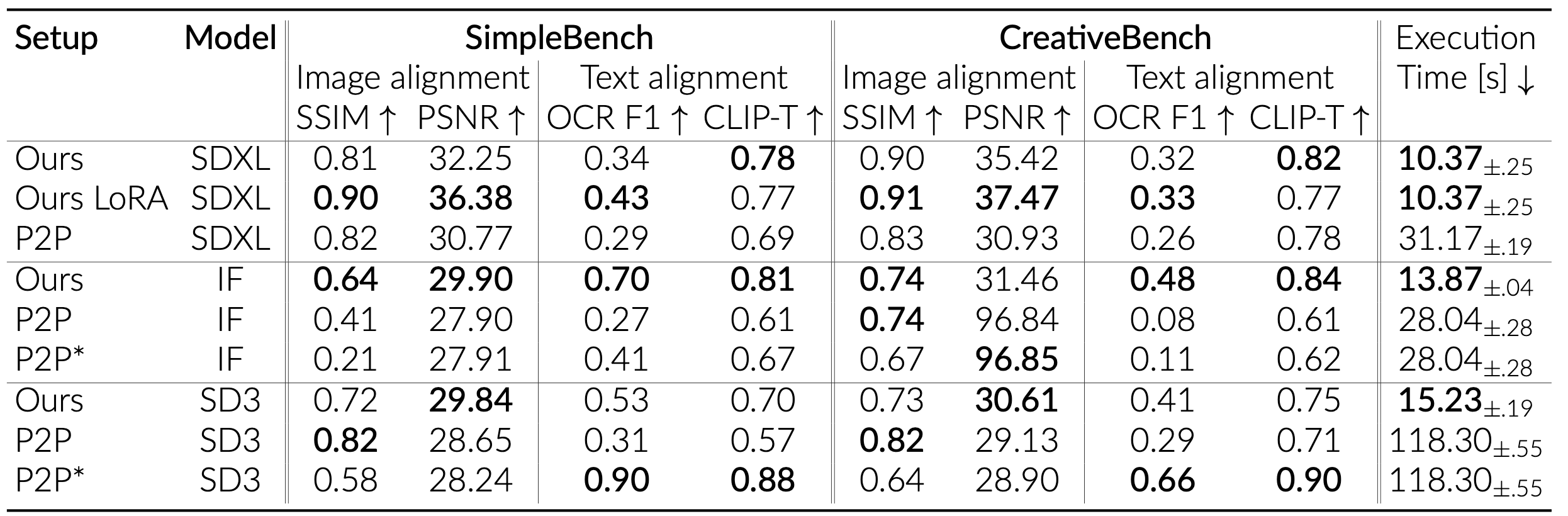
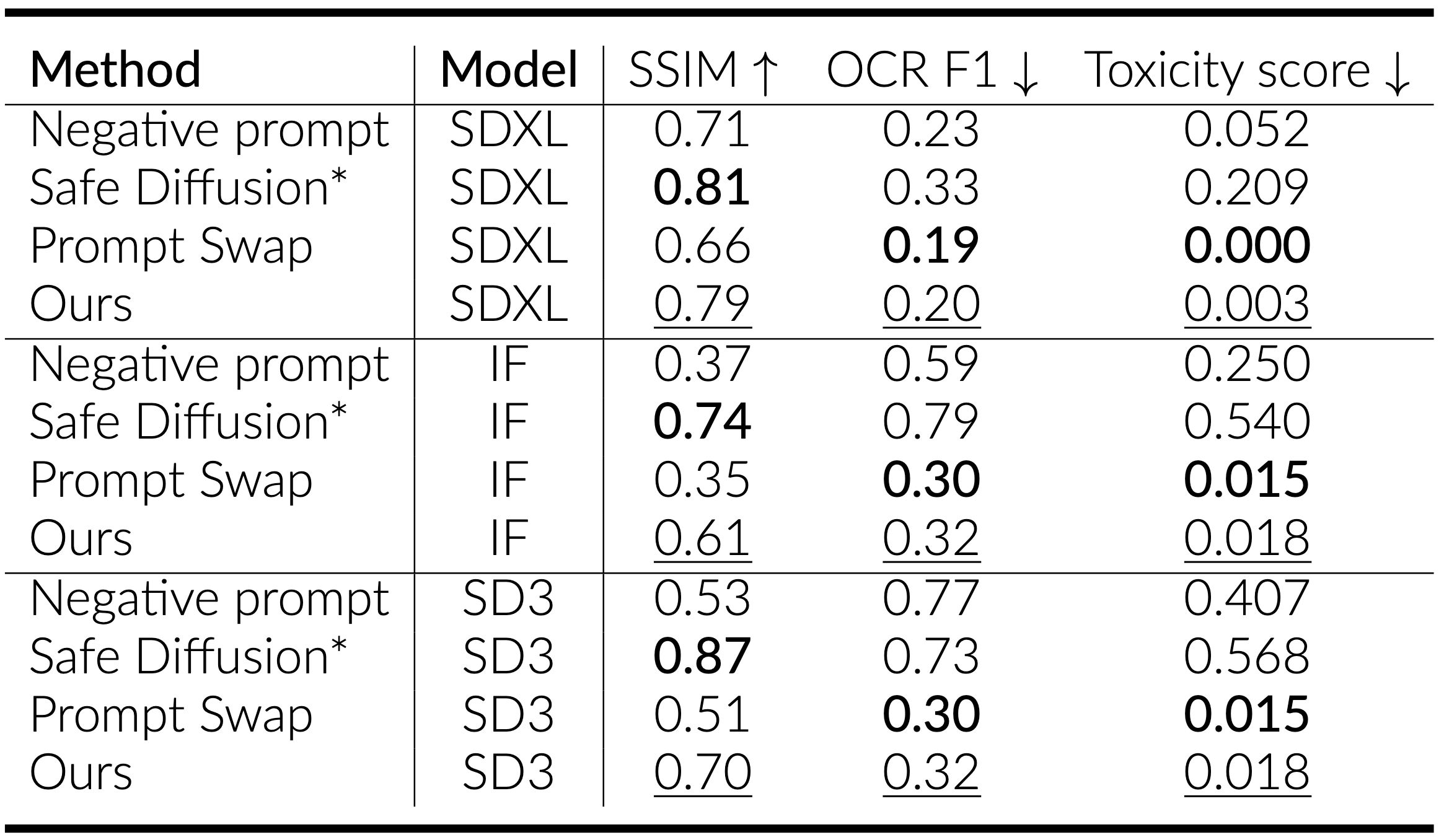
Using our localization approaches, we identified three layers in SDXL (55, 56, and 57), one layer in DeepFloyd IF (17), and one layer in SD3 (10). These layers, when patched, cause the diffusion models to produce the text that closely matches the text in the target prompt. Most notably, this constitutes to less than 1% of the total model parameters.